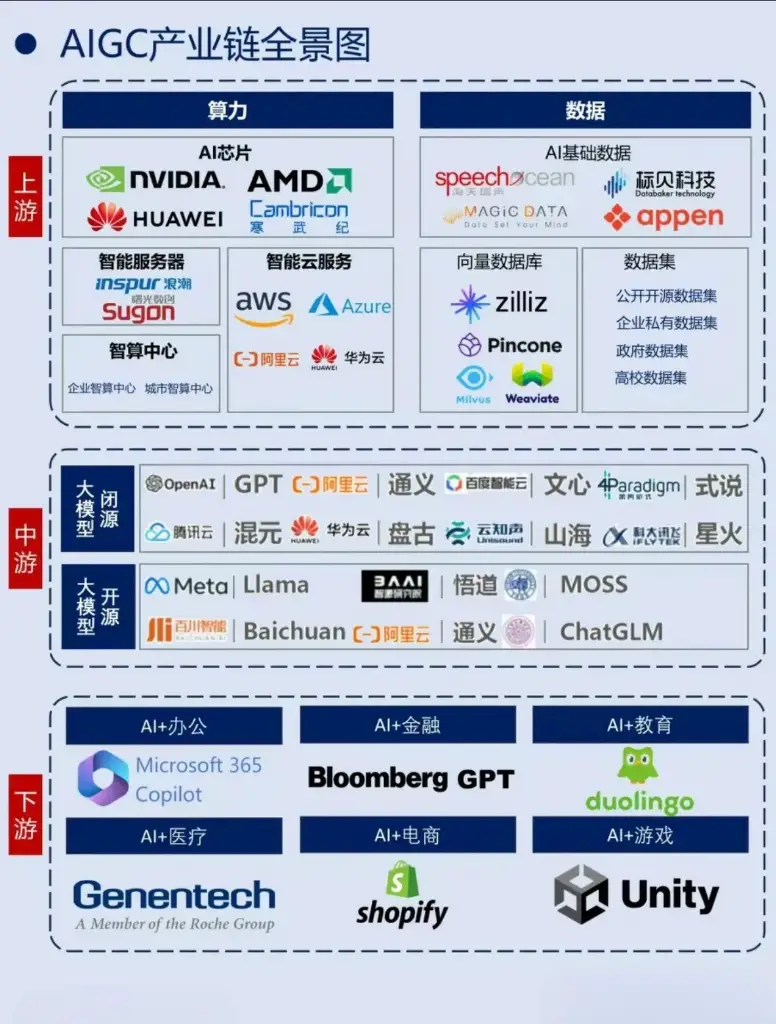
AIGC产业链 — 生成式人工智能
现在真正好用的AI工具其实也就是头部的ChatGPT、Midjourney、Llama这几个。其它基本都是蹭AI热点的,属于杂牌。建议学习和使用AI的小伙伴,抓住主线,别被多如牛毛的杂牌们给迷花了眼,掉进了坑里!
Perplexity 创始人说过,人们可以把 Perplexity 看作一个套壳产品。从那时起,“套壳之王”的称号就非它莫属了。非常多的创业公司,并不是死于套壳,而是死于并没有套好壳。例如 Poe 软件,全球用户量最高的AI软件之一,就是基础的简单套壳。
AI “套壳”的四个等级:
一阶:直接引用OpenAI接口,ChatGPT回答什么,套壳产品就能够回答什么。这阶段其实卷的是体验、UI、成本,就是怎么把这些英文的东西变成中文,怎么让速度更快,怎么让用户不用翻墙去使用国外的模型。
二阶:套壳(构建)Prompt。也就是套的提问方式。大模型可以类比为研发,Prompt可以类比为需求文档,需求文档越清晰,研发实现得越精准。套壳产品可以积累自己的优质Prompt,卷Prompt质量高,卷Prompt分发。比如经常网上看到的“小红书爆款文案的生成”、“个人的健康助理”、“个人的法律助理”等,就是套壳公司研发时已经内置了一系列的提问,内置了一系列的角色,这类套壳工具可以满足非常多日常基础的办公需求。
三阶:卷数据,就是在模型的基础上外接一个知识库(Embedding),基于这个数据集的套壳,就是让AI能够了解过去10年,甚至更长时间的客户,让客户可以更丝滑的跟它对话,基于过去所有的数据和经验来完成客户的需求。换句话说, 嵌入特定数据集,把特定数据集进行向量化,在部分场景构建自己的向量数据库,以达到可以回答ChatGPT回答不出来的问题。比如垂直领域、私人数据等。Embedding可以将段落文本编码成固定维度的向量,从而便于进行语义相似度的比较,相较于Prompt可以进行更精准的检索从而获得更专业的回答。
四阶:调用微调 Fine-Tuning,使用优质的问答数据进行二次训练,让模型更匹配对特定任务的理解。相较于Embedding和Prompt两者需要消耗大量的Token,微调是训练大模型本身,消耗的Token更少,响应速度也更快。这阶段的套壳,也就是所说的翻译成,除了基础的API之外,它就已经针对这个大模型,非常的面向深度使用的企业了,这时个人用户其实不太会用得到,且这种类型的套壳会需要非常资深的AI研发人员去直接做修改。可以理解为:它就是一个人的开脑手术,把脑打开,然后在里面去植入一些新的细胞,新的记忆,有可能如果植入不好的话,脑子里其他东西都会发生一些偏移、转化和损坏,但是如果植入的好,这个东西就变成天然属于你的,它不是一个额外的专家团,不需要有问题再去问它,你天然就知道这些所有的知识。
这就是对于整个的套壳之后的这个模型去做微调,微调之后,全世界就是一个专属于你的模型,也只是你的知识。当然这种套壳的成本也是非常之高的,它会需要针对大模型里面的数据去做非常精细化的调用,并且它的失败成本是极高的,它应该不会是绝大部分企业在今天去拥抱AI所需要做到的事情。当然,如果把现在市面上的开源模型,比如Mata的Llama,或者通义千问的框架,直接拿下来去做模仿训练,把自己所有的数据开始给这个开源的模型去做训练,这个可以认为是套壳隐藏的第五层,就是完全去开发一个自己的大模型。
参考视频 “软件套壳的5个阶段” =作者“宏力Chris”
AIGC 产业链
“郜铖讲股权”视频:揭秘ChatGPT独特的股权设计

 |
 |
 |
 |
OpenAI、Google、Kimi 都在「Perplexity化」
Key Points :
- 外界称Perplexity为「AI搜索」,它更喜欢自称「答案引擎」;它使用的都是第三方模型,其中既有GPT也有Gemini和Claude,Perplexity提供了一个新东西——确定性。它还提供一种非常有用的功能,即允许用户将搜索范围限制在特定数据库中,比如你可以要求它将检索范围限定为YouTube、Reddit,也可以是特定学术期刊。
- Perplexity团队中不少成员来自Quora,Perplexity本身也很像一个AI版知乎;「虽然每个人都有很强的好奇心,但能将好奇心转化为精确问题的人很少。」Perplexity因此花了大量时间在处理、分析和重组用户查询的问题上,也就是说,当用户提出相对含糊的问题后,Perplexity会首先将问题处理成更有逻辑的提问方式,即优化用户的Prompt后,才将问题交给模型回答。
- 「微调」还是「搜索增强」?市场已分为两大阵营;让Perplexity不同于Google的是答案引擎,而让Perplexity不同于ChatGPT的,是被称作RAG(Retrieval-Augmented Generation)的检索增强生成技术。顾名思义,这种技术使大型语言模型(LLMs)可以连接到外部知识库,利用从外部来源获取的事实提高生成式AI模型的准确性和可靠性,减少模型本身的「幻觉」。RAG技术可以与任何外部数据源连接,通过它,用户基本上可以与任何数据存储库对话。几乎每家企业都有属于自己的知识资产、数据库,过去,以OpenAI为代表的大模型公司提出以「微调」的方式为各垂直领域客户提供服务,即它倡导用各企业的内部数据继续训练大模型公司们提供的基础模型,从而推出一个更懂某家公司的专有模型。
- Perplexity的产品哲学:1.用户永远不犯错;2.把产品做深;产品形态上,Perplexity位于搜索引擎Google和聊天机器人ChatGPT之间,除了问答窗口、「相关问题」,它还有一个叫「发现」(Discover)的选项卡,里面有大量人为选择的当日新闻摘要供用户浏览和继续追问。与ChatGPT或Gemini相比,「发现」选项卡使得用户了解全球正在发生的新闻变得更加容易。
文章来源 “谁是Perplexity?”
